




GEOTRA Activity Dataによる移動目的の推定
GEOTRA Activity Dataには移動目的という項目を追加していて、トリップエージェント(IDが付いている方 )が移動した時の移動目的をデータの中に付与しております。
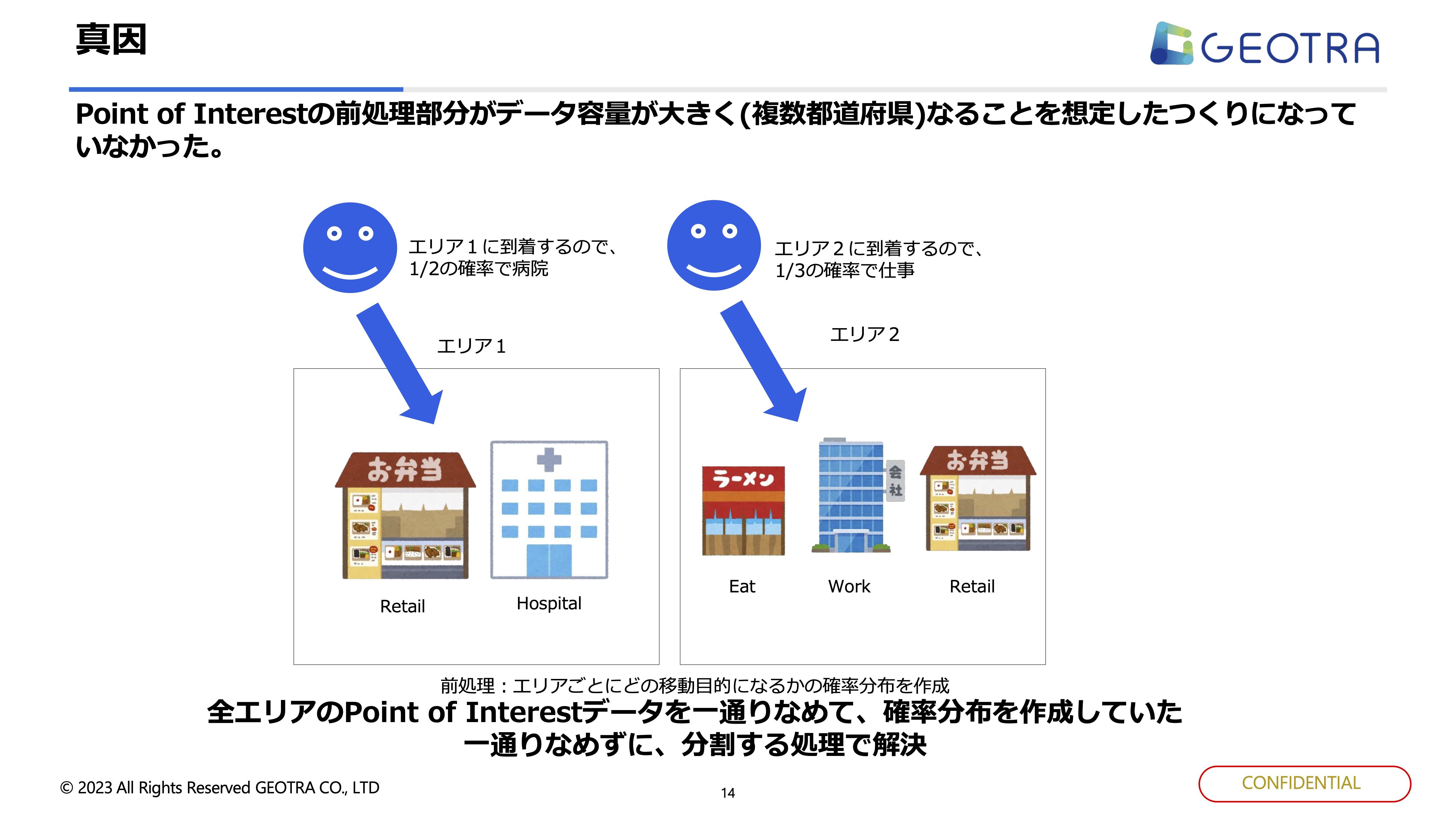
付与するロジックは基本的に到着地点です。例えば、病院に行っていればHospital(通院)が目的だと判断します。

先ほどのHospitalのようなデータはPoint of Interstデータと呼ばれるのですが、建物が何かで移動目的を切り替えています。例えば、ラーメン屋→Eat、会社→Work、 小売事業者→Retail、病院→Hospitalといったデータをトリップデータとは別に日本中の様々な建物情報を持っています。

移動目的を紐付ける際はトリップデータとPoint of Interestデータを掛け合わせて、トリップデータに対してPoint of Interestデータのどれが1番近いのかを処理しています。
そうすると、トリップデータ数がn個でPoint of Interestデータがm個あったら単純計算でn×m通りのパターンが存在するので、数が膨大になればどんどん増えていくのは容易に想像できるでしょう。

データの増加により処理時間が膨大に
その後、想像通り処理時間が雪だるま式に増えていくという課題にぶち当たりました。
元々事業を開始した際は基本的に街や市単位のデータだったので、ある程度お客さんの方で対応できていました。しかし、お客様に色々データを提供していくと、今度は都道府県でデータを欲しいというお客さんもいて処理時間が伸びていきました。
複数の都道府県になると処理時間もさらに増えていって、最終的には2週間経っても処理が終わらない状態になりました。

以降は試行錯誤の日々で、まずはクラウドのインスタンスサイズを4倍くらいに変えても全然変わりませんでした。

他にもトリップを64分割して分散処理したりしてもまだ変わりませんでした。

そして、最終的にトリップデータとPoint of Interestデータの両方を分割してようやく短縮できました。それぞれ64分割して並列処理で回していくと、現実的な処理時間となったんです。

今回のように対応エリアが増えた数だけ、Point of Interestデータは増えます。 処理をある程度早くするためにエリア単位でくくって、ここに来た人の2分の1の確率でこの人は病院に来た、3分の1で仕事に来た、といった処理を入れていました。
この移動の確率分布を複数の都道府県全部で見ていましたが、例えば、東京の千代田区にいる方のPOIを見つけたいのに、全然違う埼玉県のある市のデータの処理をやっていて時間がかかっていたりしました。なのでしっかりと分割して処理することが大事だと分かりました。
視聴者からの質問に答える質疑応答タイムへ
――ここからは、視聴者の方からの質問に回答していきます。まず1つ目は、「データ構造の負債を解消するために専用のメンバーを配置しているのでしょうか、それとも開発メンバーが機能アップデートと並行して進めているのでしょうか」という質問です。陳さんからご共有いただけますか。
陳:我々は全て同じメンバーがやっています。なぜなら、ここを分けると背景がわからないメンバーも入ってきてしまうからですね。 基本的に解消する際は短期間で皆で一緒にやり切るという形で進めています。
――続いてtocknさん、お願いします。
tockn:弊社も同じで、特に負債解消の専門チームは置いていません。プロダクトを開発するメンバーが解消しています。クォーターの最初の2週間は非機能系の改善に当てるといった改善ウィークも設けたりして、色んな方法でプロダクト開発と共に並行できる施策を練っている感じですね。
――続いて大島さん、お願いします。
大島:Nayose Groupは歴史が長く大きいチームになっていて、その結果システムとしても大きくなってしまいました。そのため、チームを分割してより改善しやすくなる構造にしています。
――続いて森山さん、お願いします。
森山:弊社も機能アップデートと並行してやっていますね。 開発を進めるか、負債を解消するかを天秤にかけていて、場合によっては負債の解消を優先しています。
――最後に弓場さんはお願いします。
弓場:フツパーもチームを分けてはいなくて、開発メンバーが担う体制で今はやっています。
――続けて、「どれぐらいの時間をかけて負債を解消してきましたか」とのことですが、陳さんからお願いできますか?
陳:基本的には2〜3週間でやりきることを徹底しています。 何か行動的に問題が発覚した場合は一旦開発を止めて2〜3週間で全部やりきって、無理にその先に進まないという判断をしてきました。 短期間で細かく、問題があるところだけ集中的にアタックする形ですね。
――続いてtocknさん、お願いします。
tockn:先ほどの回答と被りますが、改善ウィークみたいな形で1週間〜2週間を改善の期間に当てていますね。あとは、クォーター単位でプロダクトや非機能系の開発も含めて何をやるのかを整理する段階で期間を当てはめたりしています。
――続いて大島さん、お願いします。
大島:細かいところは2週間くらいの短期間でやって、 どうしても歴史的経緯で大規模改修が必要なタイミングであれば半年〜1年ぐらいかけて、現在動いているものをリプレイスする形です。
――続いて森山さん、お願いします。
森山:大体メンバーは複数人いるので、一人が負債回収して、もう一人は機能開発という感じでやっていましたね。負債回収をやると大体1ヶ月ぐらいかかります。それぐらいで今回の課題などは対応していました。
――続いて弓場さん、お願いします。
弓場:今回発表したデータベースの移行に関してはいきなり全部を変えるのではなくて、ステップを区切って1ヶ月単位で行いました。
――本日のイベントはこちらで終了とさせていただきます。 登壇者の皆さん、視聴者の皆さんありがとうございました。


