


セマンティック検索の改善は非経済合理的である
セマンティック検索は未学習の単語に対してベクトルを生成する能力が低いのが弱点です。そのため、専門用語や固有名詞、自社内のみで使う用語は検索をかけてもヒットしません。
しかし、RAGを改善するために、Embeddingモデル自体を改善するのは非経済合理的です。ベクトル検索はあくまでも文章の類似性の特定が得意な手法なので、 質問に対する回答が全く異なる意味だったり、用語が専門的すぎてベクトル検索に対してEmbeddingできない問題が出てきてしまいます。


HydeやRag fusionを使用しても依然として課題は残る
セマンティック検索の問題に対応するために、RAGの周辺技術であるHydeやRag fusionを使用することが思いつきますが、それぞれ問題があります。
Hydeでは生成した仮の文章とドキュメントをマッチングさせて検索します。しかし、1回文書を生成しなければいけない分、速度が課題です。Rag fusionはクエリを与えられた時にLLMで生成した複数のクエリから生成したドキュメントをマッチングさせる仕組みですが、曖昧なクエリだと複数のクエリも曖昧になってしまいます。

ハイブリッド検索とリランキングで検索精度を改善する試み
弊社ではハイブリッド検索とリランキングという2つの手法を用いて問題を解決していきました。結果的には5〜10%ほどの精度改善が見込めました。
ハイブリッド検索はキーワード検索とベクトル検索を組み合わせた手法です。 キーワード検索はGoogle検索と同様で、単語の品質を文章の長さによってスコアを出す仕組みになります。文章全体の意味を特定できるベクトル検索の良さをキーワード検索と掛け合わせて精度を上げていきます。

キーワードとベクトル検索の融合方法は順位に基づいたスコア(逆順位融合)と加重平均の合計スコアで最終的なスコアを算出する形です。

学術的な指標を用いると、ベクトル検索ではFAISSとOpenAIのtext-embedding-3-largeを使用しています。キーワード検索にはOkapiBM25(キーワード検索の中では1番精度がいいと言われているアルゴリズム)を使用します。
使用するデータセットは弊社の資料(170チャンク)で、クエリとドキュメントが1対1でも紐付いているものです。
評価仕様にはMRRとRecallを使用します。MRRはユーザーの正解を4番目に出したものと1番目に出したものがあったとしたら、1番目に出した方がスコアが高いという仕様です。Recallは、例えばユーザーに5個おすすめしてその中に正解が含まれているかどうかという指標です。

そして、結果は以下の通りです。RFF hybridに関しては先ほど説明した逆順位融合(Reciprocal Rank Fusion)で、その下はweighted sum hybridです。ベクトル検索やキーワード検索とともに高いスコアを出しており、精度が向上しているのが分かります。

続いてリランキングです。リランキングとは、RAGの検索をかけた後にもう一度同じ文章クエリが正しいかどうかをランキング付けするモデルです。例えば、取得した50個のドキュメントの中で上から5個の文章を並べ替えます。

今回はCohereのリランキングAPIを使用しています。結果はhybridでは精度の向上が見られませんでしたが、ベクトル検索とキーワード検索では著しい精度改善が見られました。特にMRRでは先ほどの指標よりも15〜16%ほど改善しています。

ここで注意ですが、ハイブリッド検索によって精度が下がる場合があります。あるデータセットではキーワード検索が足を引っ張って性能が上がらないケースもあります。 また、リランキングには今回CohereのAPIを使用しましたが、コストが結構かかってしまいます。

その一例としてデータセットを使用して検証したところ、ベクトル検索やキーワード検索、hybridでは改善しませんでした。しかし、hybridのrerankモデルを使うと数%ほど改善しました。

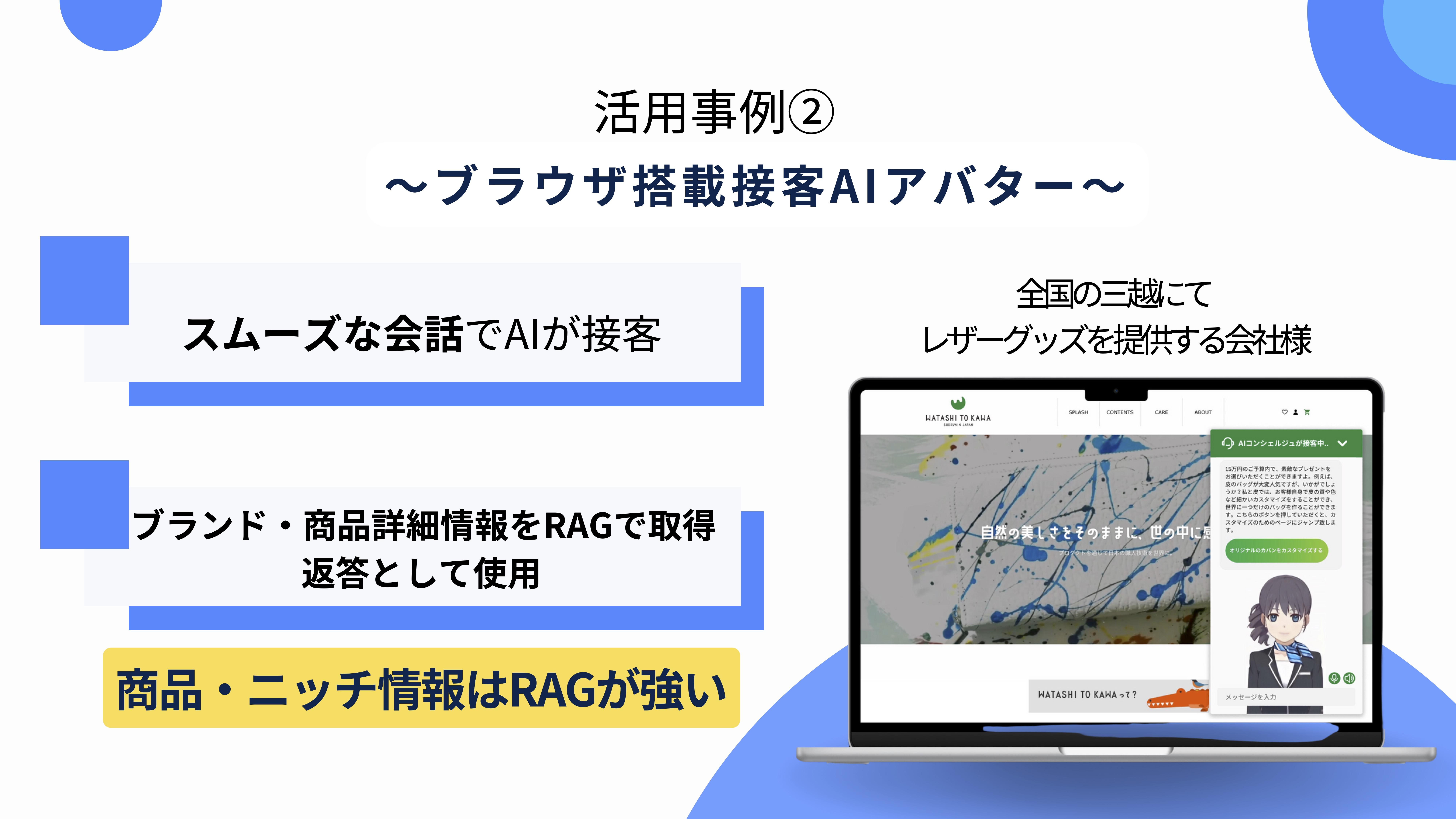
RAGを活用したAIが電話対応や接客業務を担う
実際には、架電業務に特化したnocall.aiというAI電話オペレーターサービスのプロダクトにRAGを活用しています。nocall.aiは人間のようにAIと対話できるのが特徴であり、リマインドの自動化やSaaSオンボーディングのサポート、インサイドセールス電話の自動化などに使われます。
RAGを導入することで、お客様の多岐に渡る内部データへの検索精度が上がって、対応品質の向上に繋がっています。

また、ブラウザ搭載の接客AIアバターも提供しております。画面右下に接客AIアバター(コンシェルジュ)を表示させて、スムーズな会話でAIが接客してくれるサービスです。
実際にアパレルブランドのお客さんから、ブランドや商品情報をRAGで取得したいという要望がありました。自社商品などのニッチな情報にはRAGが強いです。
丸岡氏のコメントと視聴者からの質問に答える質問タイムへ
――まずは丸岡さんの方から技術的な観点やコメント等がございましたらお願いします。
丸岡:初めてプロダクトを拝見しましたが、非常に応答速度が早いと感じます。言える範囲で構いませんので、工夫されているところはありますか。
森本:応答速度は大体1秒以下でできるように作っています。認識した瞬間から処理するイメージです。基本的に私たちのプロダクトは文字起こししてからGPTに投げて、Text-to-Speechで情報をリアルタイムで流す形にしています。
――「RAGの精度評価について、パフォーマンスはどのように評価していったのでしょうか」とのことですが、いかがでしょうか。
森本:基本的にテストデータはドキュメント1個に対してクエリ1個で作りました。ドキュメント全体を見て我々で一旦クエリを書いてから、ChatGPTを使って水増しする形でデータを作成しました。
丸岡:色々試されてハイブリッドに落ち着いたとのことですが、速度面の性能で選ばれたのでしょうか。
森本:そうですね。我々のプロダクトは速度を重視しているので、ユーザーの応答前にクエリの処理をするものは速度的に採用できませんでした。
丸岡:最近GPT-4oも速くなったと言われますが、4と比べても遜色ない速度ではないでしょうか。
森本:4oの内部構造が分からないのではっきりとは言えないですが、4oは0.3秒程度で返すようです。我々は文字起こし→ChatGPT→結果を喋らせるという3段階のステップを踏んでいます。最近発表されたGPT-4oは音声とプロンプトを入れて音声を出すモデルを使用しているのではないかと推測しています。


